Chapter 6 describes runtime behavior: how building blocks collaborate in the scenarios that matter, including alternatives, exceptions, and the bits that tend to hurt in production. It is also the third chapter in the "How is it built and how does it run" group.
In this article I show what belongs in chapter 6, what to keep out, a flexible structure you can copy, plus a small example from Pitstop.
This post is about chapter 6: Runtime view,
the third chapter in the “How is it built and how does it run” group.
Chapter 5 gave us the map (building blocks and responsibilities).
Chapter 6 shows how that map is used in real life: who talks to whom, in what order, and why.
The arc42 template keeps this chapter intentionally “empty” by default.
It is basically a container for scenarios: one subchapter per runtime process you want to document.
Note
Chapter 6 can grow a lot. That is not a smell.
If users and external neighbors interact with your system, those flows are architecture.
How does the system behave at runtime in the scenarios that matter?
What belongs here:
All relevant runtime scenarios where there is meaningful interaction:
user interactions that change state or trigger workflows
integrations with external neighbors (inbound/outbound)
operationally important processes (batch runs, scheduled jobs, import/export)
flows that embody key quality goals (latency, availability, auditability, resilience)
For each scenario: the collaboration between the building blocks (names consistent with chapter 5).
Alternatives and exceptions where they exist:
timeouts, retries, idempotency, partial failures, degraded/offline behavior, manual fallbacks.
Notes that help people reason about runtime behavior:
correlation IDs, observability points, ordering guarantees, consistency expectations.
Tip
If a neighbor appears in the context view (chapter 3), try to let it show up in at least one runtime scenario over time.
If it never appears, that is useful feedback: maybe it is not a real neighbor, maybe it is background data, or maybe the relevant scenario is still missing.
Either way, treat it as a prompt to revisit the context view in your next iteration.
What does not belong here:
Long descriptions of static responsibilities and decomposition.
This chapter is about collaboration over time, not “what exists”.
A full contract catalog or protocol reference.
Link to specs where they live; keep this chapter focused on behavior and responsibilities.
Environment-specific deployment details.
The runtime behavior should still make sense even if you deploy differently.
Low-value diagram noise:
repeating “return payload” on every arrow when nothing is transformed,
or expanding every internal hop when it adds no architectural insight.
Cross-cutting flows that are the same everywhere, such as the OAuth/OIDC login flow.
That belongs in chapter 8 as a reusable concept (unless you are literally building an auth service 😅).
Note
Runtime view is where architecture stops being a set of boxes
and becomes a set of promises: “this happens”, “this must not happen”, “this is how we recover”.
Diagrams (and how to keep them readable)
Sequence diagrams for sequential flows
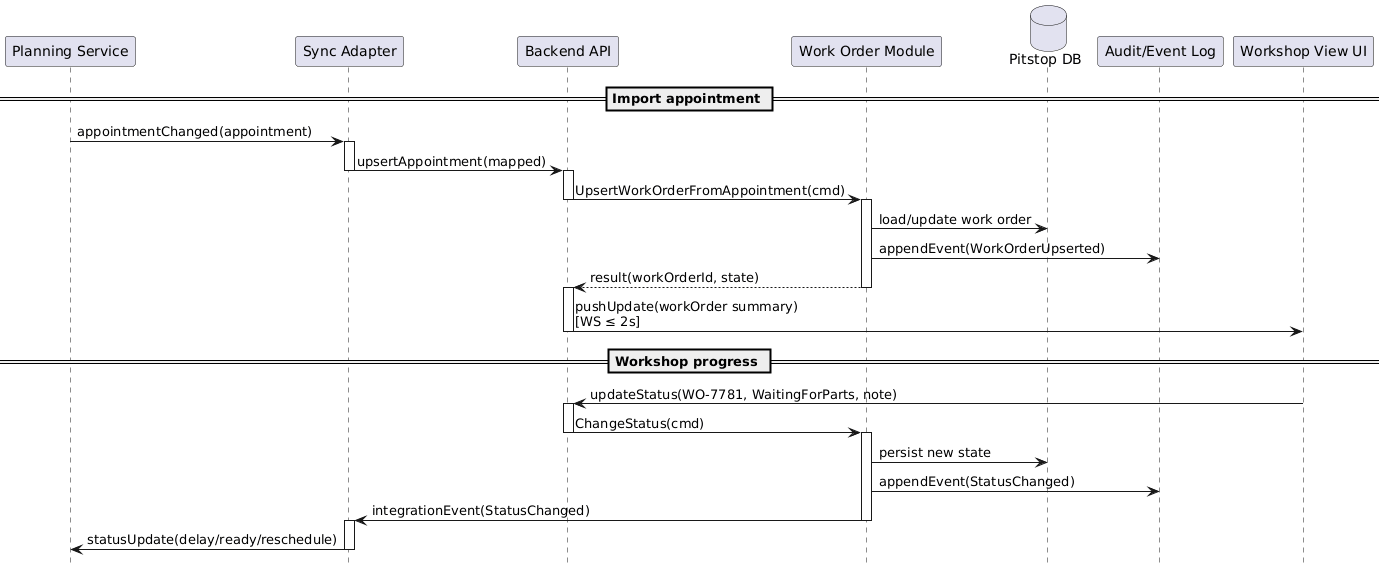
Sequence diagrams are excellent at showing who talks to whom, in what order, and why it matters.
Focus on what changes to keep diagrams readable:
Request/response pairs
Show them only when data transforms or meaning shifts.
Skip the “return OK” arrows that just echo back what was sent.
Internal hops
Compress them when a layer simply passes data through without adding architectural insight.
Three layers calling each other with identical payloads? Show it as one arrow across the boundary.
Scenario intent
Lead with it, not implementation noise.
Readers should grasp the essential flow in seconds, then dive into details if they need them.
Example trade-off
A “create order” scenario does not need you to diagram every internal service call.
Show the user action, the boundary entry point, the database write, and the response back.
Skip the middleware, logging, and validation layers unless they embody a quality goal or failure path.
BPMN for more complex flows
When scenarios have a lot of branching (alt/if/else), loops, delays, sequence diagrams can become a spaghetti scroll. 🍝
That is where BPMN often shines: it stays readable as complexity grows.
Camunda Modeler is my go-to tool.
Trade-off: BPMN is typically stored as XML, which is not fun to review in a repo.
So exporting diagrams as images becomes an extra step.
Just keep the source file and the exported image together.
Tip
You do not need to pick one diagram type for everything.
Consistency helps, but clarity helps more.
The minimum viable version
If you are short on time, aim for this:
Start with 1–3 scenarios that cross boundaries: user → system and system → neighbor.
The first user flow, the first integration, and the first “what if it fails?” path.
Conflicting edits → “last-write-wins” only for safe fields; status changes may require rules (e.g., foreman override).
To browse the full Pitstop arc42 sample, see my GitHub Gist.
Common mistakes I see (and made myself)
Only documenting the happy path
Architecture shows up in failure handling, retries, timeouts, and recovery.
Diagrams that do not match your building blocks
If names and boundaries differ from chapter 5, readers lose their mental model.
Diagram noise instead of insight
Do not waste pixels on repetitive returns and unchanged payloads.
Compress internal hops when they add no architectural value.
User → API → Service → Repository → DB → Repository → Service → API → User
User → API → Domain write (DB) → API → User
Avoiding “big” because it might become big
Documenting 27 scenarios is not wrong.
It becomes wrong when nobody can find anything.
Group them, index them, or split into linked documents when the system is large.
No external stakeholder recognition
If a neighbor/system owner cannot recognize their part in the flow,
you probably did not document it clearly enough.
Done-when checklist
🔲 Relevant user and neighbor interactions are covered (or explicitly postponed). 🔲 Scenario diagrams use building block names consistent with chapter 5. 🔲 Key alternatives/exceptions are documented where they matter. 🔲 The chapter is navigable: scenarios are grouped and titled clearly. 🔲 Readers can explain “what happens when…” without guessing.
Next improvements backlog
Add scenarios for remaining neighbors until the context view is “explained by runtime”.
Add idempotency/retry rules for integrations that can duplicate messages.
Add observability notes per scenario (correlation IDs, key logs/metrics).
Split scenarios into separate linked arc42 documents if the system warrants it.
Wrap-up
Chapter 6 is where your architecture becomes visible in motion.